
DeepSeek
Authors | Jiang Yu, Chen Junda
DeepSeek officially released and open-sourced the preview version of the DeepSeek-V4 series on April 24, marking a new generation flagship model system following V3.2. The impact of DeepSeek V4, dubbed “Source God,” was remarkable, quickly trending on Weibo, occupying three of the top five spots, second only to Xiaomi’s YU7GT.
This release includes two models: DeepSeek-V4-Pro and DeepSeek-V4-Flash, utilizing MoE architecture, with a total parameter scale of 1.6T (activated 49B) and 284B (activated 13B), respectively, both supporting a maximum context of 1 million tokens.
DeepSeek noted that due to high-end computing limitations, the service throughput of DeepSeek-V4-Pro is currently quite limited, but prices are expected to drop significantly after the release of the Ascend 950 super nodes later this year. Additionally, DeepSeek-V4 has received Day 0 adaptation support from Cambrian, with related adaptation code open-sourced to the GitHub community.
DeepSeek-V4-Pro focuses on performance limits, competing with closed-source flagship models, while DeepSeek-V4-Flash significantly reduces parameter and activation scales for lower latency and cost.

Compared to the previous generation, it has further improved in Agent capabilities, world knowledge, and complex reasoning tasks, and for the first time, offers “million token context” as a default feature.
In terms of Agent capabilities, DeepSeek-V4-Pro shows significant enhancement. It ranks among the top open-source models in evaluations like Agentic Coding, with internal assessments indicating delivery quality nearing Claude Opus 4.6 in non-thinking mode, though still lagging behind in thinking mode.
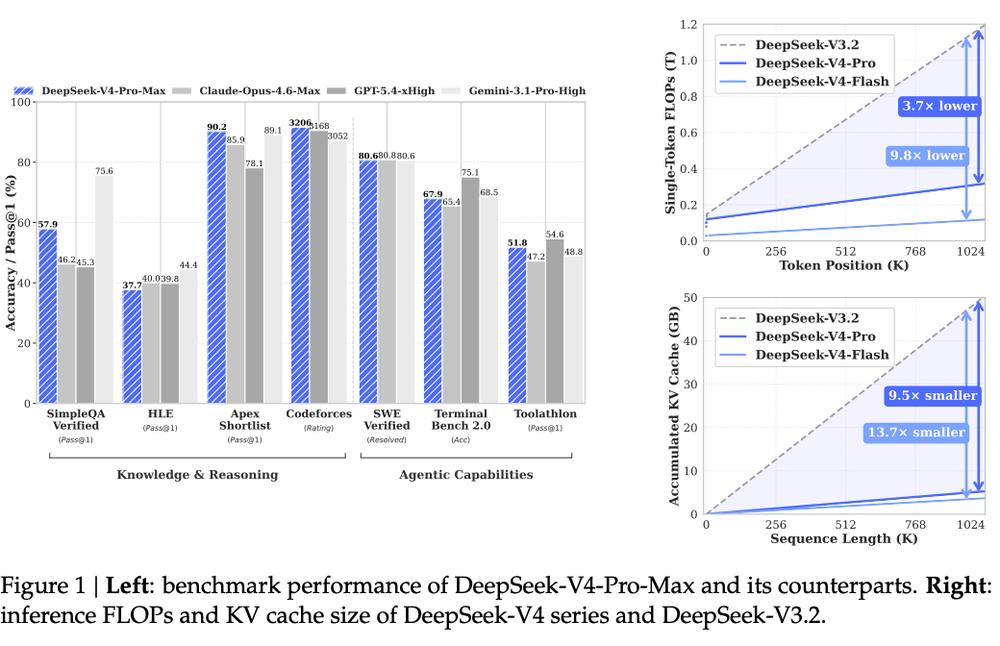
DeepSeek-V4-Pro has surpassed currently available open-source models in high-difficulty tasks such as mathematics, STEM, and competitive coding, with overall performance comparable to or even rivaling top closed-source models like GPT-5.4 and Claude Opus 4.6-Max.
Moreover, DeepSeek-V4 has introduced aggressive optimizations for long context efficiency: in 1 million token scenarios, its single-token inference computational load is only 27% of that of V3.2, and KV Cache usage has dropped to about 10%, significantly reducing computational and memory costs for long-chain tasks.
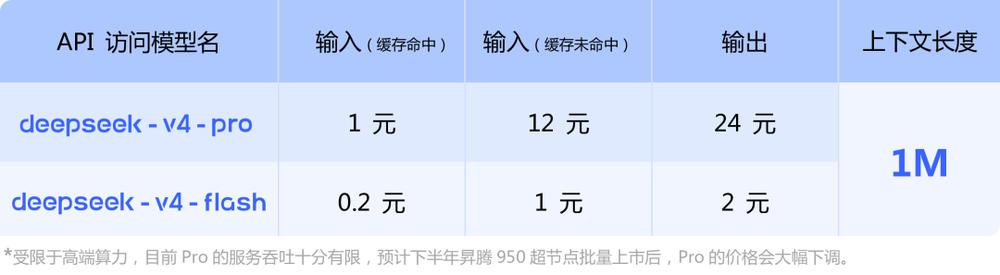
The official API pricing for the DeepSeek-V4 series has been announced: DeepSeek-V4-Pro costs 1 yuan/million tokens for cache hits, 12 yuan/million tokens for cache misses, and 24 yuan/million tokens for output; DeepSeek-V4-Flash costs 0.2 yuan/million tokens for cache hits, 1 yuan/million tokens for cache misses, and 2 yuan/million tokens for output.
Currently, the DeepSeek-V4 series is available on the official website and app, with APIs and model weights also open.
Experience link: chat.deepseek.com or DeepSeek official APP
API documentation:
https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
Open-source links:
https://huggingface.co/collections/deepseek-ai/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
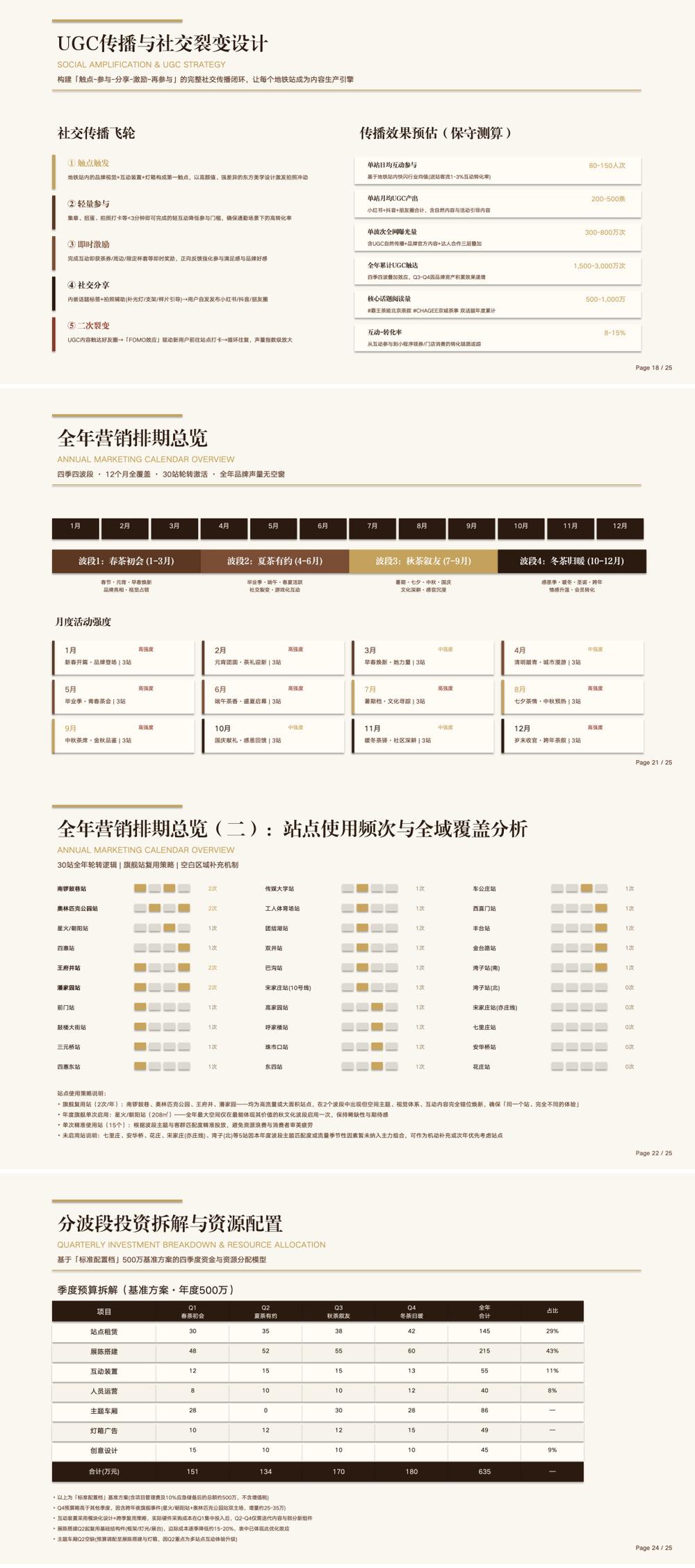
Technical report:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
1. Significant Improvement in Agentic Programming Capabilities, Consuming 540,000 Tokens for the Three-Body Trilogy
We initially experienced the changes in DeepSeek-V4, primarily testing the DeepSeek-V4-Pro model.
In a front-end web one-shot case, DeepSeek-V4-Pro demonstrated high execution efficiency. Since our requirements were not complex, the model took only 5 seconds to think and then quickly proceeded with development, a marked improvement over previous DeepSeek models that wasted many tokens during thinking.
During the actual generation process, the output length of DeepSeek-V4-Pro was significantly longer than that of other DeepSeek models. Its generation speed was fast, capable of outputting in units of 5 lines of code.
The final output of DeepSeek-V4-Pro is as follows, showing a higher completion level for the website compared to DeepSeek-V3.2, with a richer design.

Website link: https://mcp.edgeone.site/share/9pD1cRzY1QA8bmmBLDZ8S
However, this simple programming task was no challenge for DeepSeek-V4-Pro. We attempted to have it complete a task combining Agent capabilities and programming: planning a trip to Shanghai and integrating all relevant information into a travel website with corresponding location markers.
During execution, it was evident that DeepSeek-V4-Pro could perform complex multi-round tool calls, and the number of online search entries increased compared to previous models, leading to more comprehensive information gathering.

Ultimately, DeepSeek-V4-Pro collected complete itinerary information, with a reasonable plan and location markers for each attraction, which could be directly used in navigation apps, making it very convenient. In the Agent task, its actions were decisive, with tool calls and thinking resolved within seconds, showing good token efficiency.
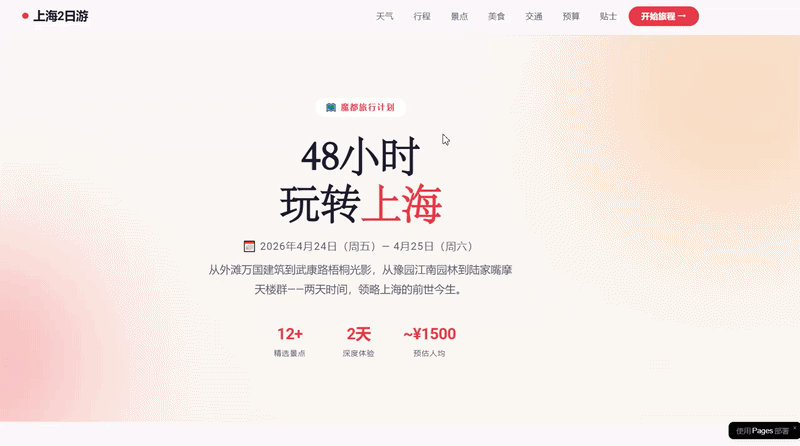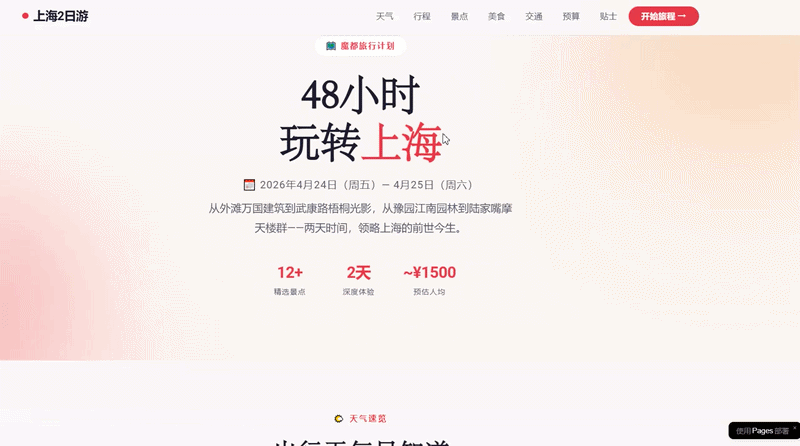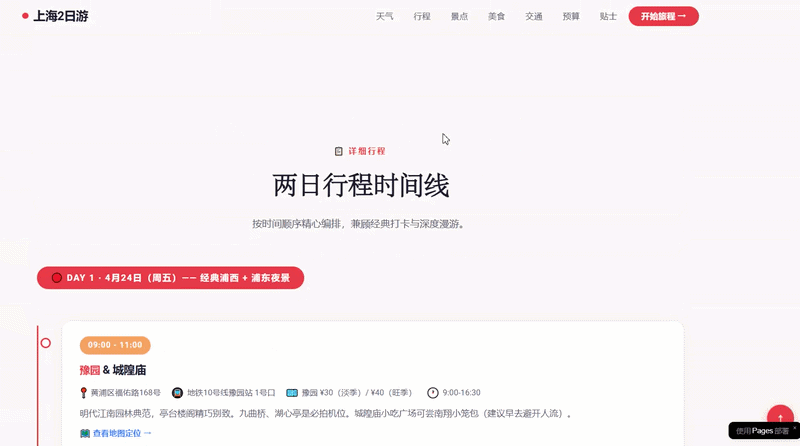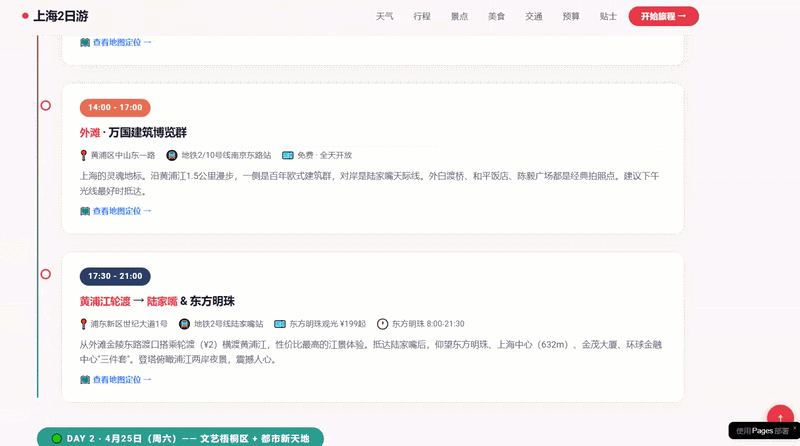
Website link for the travel plan using Agent and programming capabilities: https://mcp.edgeone.site/share/4TxFYOy24bgaEwxFoxisj
Our next case involved long text. The DeepSeek-V4 series models often boast their ability to process the entire Three-Body Trilogy in one go, and we uploaded the complete trilogy as requested.
After uploading such a lengthy document, DeepSeek was able to quickly locate the specified content, successfully achieving a needle-in-a-haystack search. However, this capability for ultra-long context comes at a cost, consuming 540,000 tokens just to output that specific content.
We also tested the model’s knowledge cutoff date by asking, “What model has OpenAI updated to?” and found that DeepSeek-V4-Pro’s knowledge cutoff is still set at 2025.

Additionally, this model currently does not support visual capabilities; uploading images still results in text extraction, and images without text display as unprocessable.
2. Million Token Context as Standard, New Architecture Reduces ‘Long Task Costs’
The most direct change in this generation V4 is making “long context” a default capability.
Unlike traditional methods that simply extend the window, DeepSeek-V4-Pro introduces a new hybrid attention architecture, combining Compressed Sparse Attention with High Compression Attention (HCA), along with DSA sparse attention for token dimension compression.
Furthermore, the model introduces manifold constraint hyperconnections (mHC) to enhance traditional residual connections and utilizes the Muon optimizer to improve convergence speed and training stability. This series of designs allows the model to “remember longer” while effectively controlling computational costs.
According to official data, under 1 million token context, DeepSeek-V4-Pro’s single-token inference TFLOPs have decreased by approximately 3.7 to 9.8 times compared to DeepSeek-V3.2, with KV Cache usage dropping by 9.5 to 13.7 times.
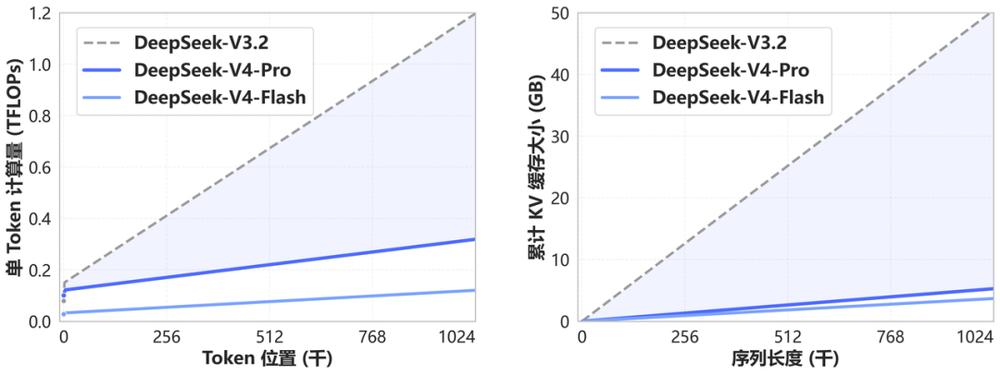
This means that previously unfeasible ultra-long chain tasks (such as multi-round Agent planning and long document processing) are now executable.
3. Inference, Knowledge, and Code Performance Boosts, Open-Source Models Approach Closed-Source Limits
From a capability structure perspective, DeepSeek-V4-Pro’s enhancements are a simultaneous elevation in inference, knowledge, and Agent capabilities.
In knowledge and reasoning tasks, it surpasses current mainstream open-source models in evaluations like SimpleQA, Apex, and Codeforces, and approaches GPT-5.4 and Gemini 3.1 Pro in multiple tasks. For example, it achieved 90.2 points in the Apex Shortlist, surpassing top closed-source models; in competitive tasks like Codeforces, it also maintains a top-tier level.
In tasks related to Agent capabilities, DeepSeek-V4-Pro shows stable performance in metrics like SWE Verified and Terminal Bench, achieving 80.6 in SWE Verified, close to Claude Opus 4.6 and significantly higher than most open-source models. Its performance also exceeds models like GLM-5.1 Thinking and Kimi K2.6 Thinking.
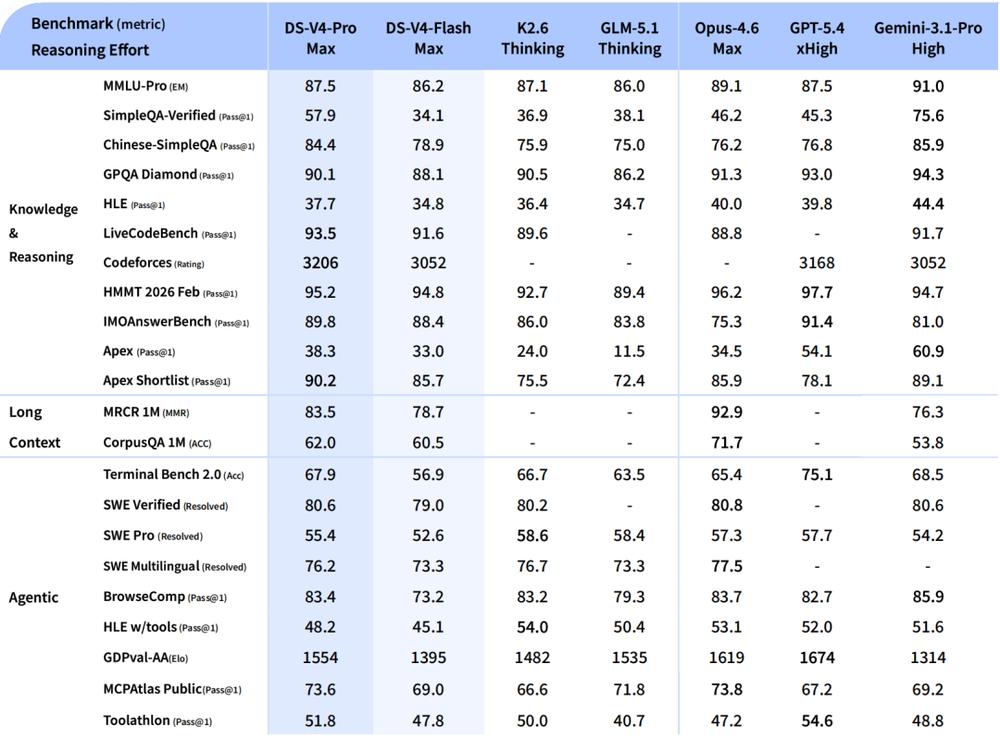
Overall, DeepSeek-V4-Pro has reached the current ceiling for open-source models.
4. Specialized Optimization for Agent Capabilities, Refining Around Real Workflows
This generation of DeepSeek-V4 has clearly strengthened its adaptation to Agent scenarios. It has undergone specialized optimization for mainstream Agent frameworks like Claude Code, OpenClaw, and CodeBuddy, showing more stable performance in multi-step tasks like code generation and document generation. The following image shows an example of a PPT page generated by DeepSeek-V4-Pro under a certain Agent framework:
From a practical standpoint, DeepSeek-V4-Pro has been internally adopted by DeepSeek as an Agentic Coding model, focusing on “task completion.” In simple tasks, V4-Flash can already match the Pro version closely, while in complex tasks, there is still a noticeable gap.
Essentially, it provides two “computational power tiers” for Agent applications. DeepSeek-V4-Flash can already compete with Pro in simple Agent tasks, but still lags in complex tasks. This difference fundamentally arises from the depth of reasoning and context utilization capabilities.
Conclusion: The Launch of DeepSeek-V4, a Beacon for Domestic Computing Power and Open Source Path
The release of DeepSeek-V4 not only showcases the team’s technological and architectural accumulation but also marks the practical landing capability of open-source large models within the domestic computing ecosystem.
Through adaptations and optimizations for domestic chips like Huawei Ascend and Cambrian, the DeepSeek-V4 series achieves stable support for million-token contexts and efficient inference, making long-chain tasks and multi-step Agent execution possible.
This version effectively differentiates the Pro and Flash models, approaching the performance of closed-source flagship models while maintaining high cost-performance for domestic developers, providing unprecedented open options.
More importantly, this release demonstrates that open-source models can not only secure a foothold in global competition but also leverage domestic computing power and optimized architectures to transform technological potential into actual productivity. DeepSeek-V4 may be a critical step for China’s open-source strength in the high-performance AI arena, providing clear guidance for innovation and implementation within the domestic AI ecosystem.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.