
Recently, research teams from Pazhou Laboratory, South China University of Technology, and AIGCode proposed Latent-Condensed Attention (LCA), with findings accepted at ACL 2026.
As a universal and efficient reasoning technology for large language models in long context scenarios, LCA breaks through the efficiency bottleneck of traditional attention mechanisms. With a lightweight, non-intrusive, and high-performance architecture design, it provides a general solution for the industrial deployment of long-text large models. In a 128K ultra-long context scenario, LCA achieves 2.5 times pre-fill acceleration, 90% KV cache reduction, and 1.8 times lower decoding latency, while maintaining original performance.
This technology can universally adapt to large models of different scales and attention architectures, such as MiniCPM and Qwen, demonstrating strong scalability and practicality. It significantly lowers the hardware threshold, inference costs, and deployment difficulty for long context large models, greatly enhancing inference efficiency and user experience.
Currently, the LCA paper and code have been open-sourced, inviting collaboration from academia and industry to advance technology iteration and application.

- Paper Title: Latent-Condensed Transformer for Efficient Long Context Modeling
- Paper Link: arxiv.org/abs/2604.12452
- Code Repository: github.com/bolixinyu/LCA
- Authors: Zeng You, Yaofo Chen, Qiuwu Chen, Ying Sun, Shuhai Zhang, Yingjian Li, Yaowei Wang, Mingkui Tan
- Institutions: Pazhou Laboratory, South China University of Technology, AIGCode, etc.
1. Challenges with Long Text in Large Models
When using large language models like DeepSeek and Qwen to process long documents and engage in deep conversations, we often encounter two major issues:
- Issue 1: Excessive Memory Usage. When processing long texts, models need to store a large amount of intermediate information (KV cache, akin to AI’s “memory”), leading to linear increases in memory usage with text length. Processing a ten-thousand-word document? It could require several GB of memory! This not only demands high hardware specifications but also significantly raises costs.
- Issue 2: Slow Processing Speed. The computational load of traditional attention mechanisms grows quadratically with text length, akin to asking someone to remember an entire book while thinking: the cognitive burden increases (high memory usage), and thinking speed noticeably declines (high computational complexity). Long text processing becomes a “test of patience.”
2. Why Existing Solutions Are Only Temporary Fixes
To tackle these challenges, previous research proposed two technical approaches:
- Multi-Head Latent Attention (MLA): The technology used by DeepSeek, which projects tokens into a lower-dimensional latent space, significantly reducing the KV cache size for each token.
- Sparse Attention: Reducing computational complexity by skipping certain attention computation blocks.
However, existing solutions often “address one issue while neglecting another.” MLA successfully saves memory but fails to escape the quadratic growth of computational load with context length; sparse attention can skip redundant computations but relies on complete Q/K/V matrices. If one attempts to combine both, it necessitates decompressing the MLA-compressed data first, akin to “compressing and then decompressing,” wasting the benefits of MLA’s lightweight design.
In the field of efficient attention for long contexts, several excellent solutions have recently been proposed, such as the sparse attention (DSA) released by DeepSeek and Kimi’s KDA. However, compared to these methods, LCA has three key differences in its technical design:

3. LCA: A New Approach to Intelligent Compression
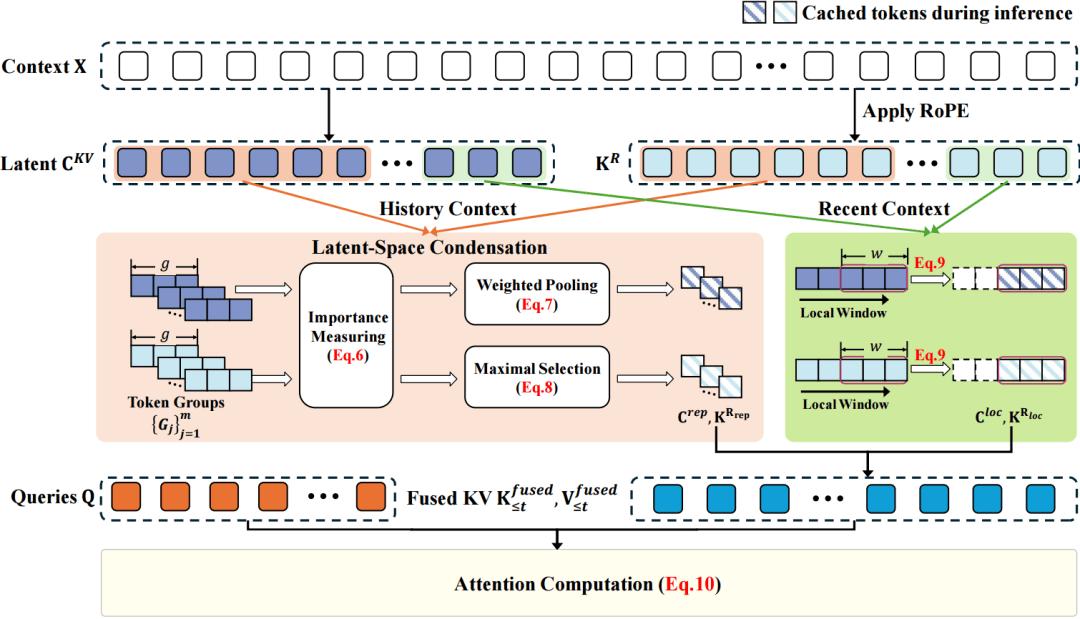
Figure 1. LCA Architecture Diagram
To solve the aforementioned problems, this paper proposes Latent-Condensed Attention (LCA), as illustrated in Figure 1. The core idea of LCA is to directly refine information in the “compressed space” of MLA rather than decompressing and then filtering.
1. Three Steps for Key Information Compression
- Step 1: Intelligent Grouping
Divide long texts into multiple small groups, each containing 16 tokens. The most recent 1024 tokens will be fully retained to ensure that the latest information is not lost.
- Step 2: Semantic Compression
Utilize an “intelligent weighting” method: based on the importance of the current query, perform weighted merging of information within the group to highlight the most relevant content. This is akin to taking notes based on exam priorities, with more detailed focus on key content. Specifically, for each semantic latent vector within the group, LCA generates a representative vector using weighted pooling:
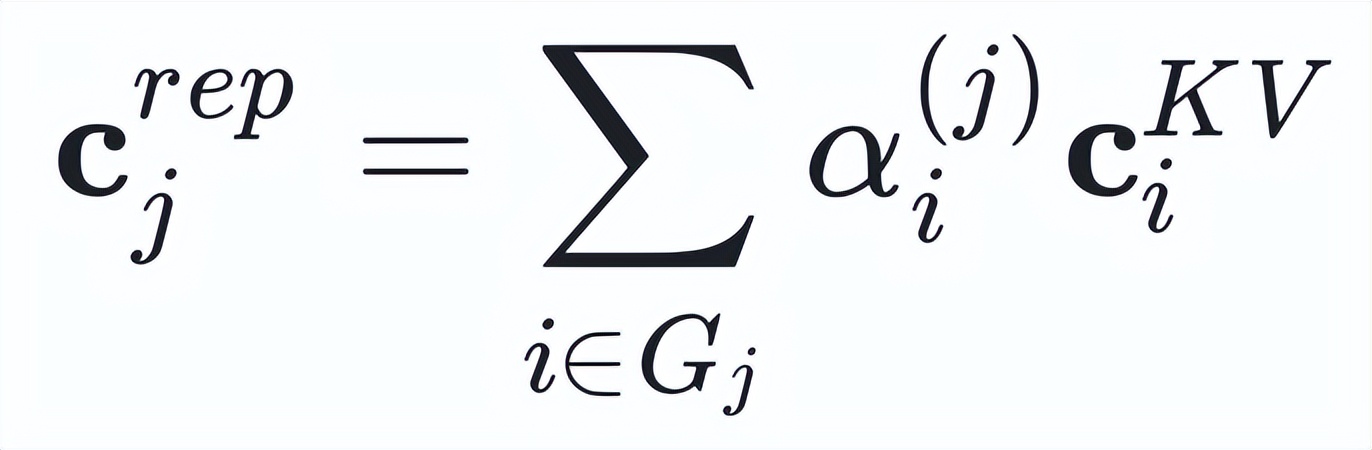

- Step 3: Position Anchoring (like tagging indexes in a book)
For the position key vectors, select the token with the highest attention score in each group as the “position anchor”:
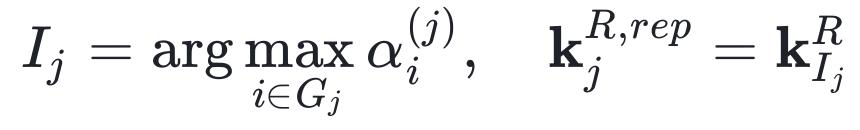

2. Retaining Fine-Grained Local Context
In addition to compressing long-distance contexts, LCA also retains a local window (default 1024 tokens) of complete latent vectors, ensuring that recent key information is not compressed, maintaining the model’s sensitivity to local details.
3. Theoretical Guarantee: Length-Independent Error Bound
This paper theoretically proves that the approximation error of LCA has a uniform upper bound independent of context length:
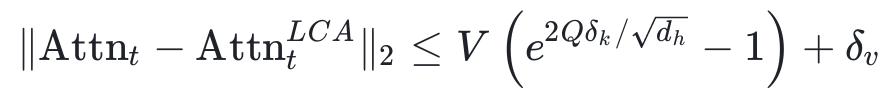

4. Experimental Results
1. Efficiency Improvement
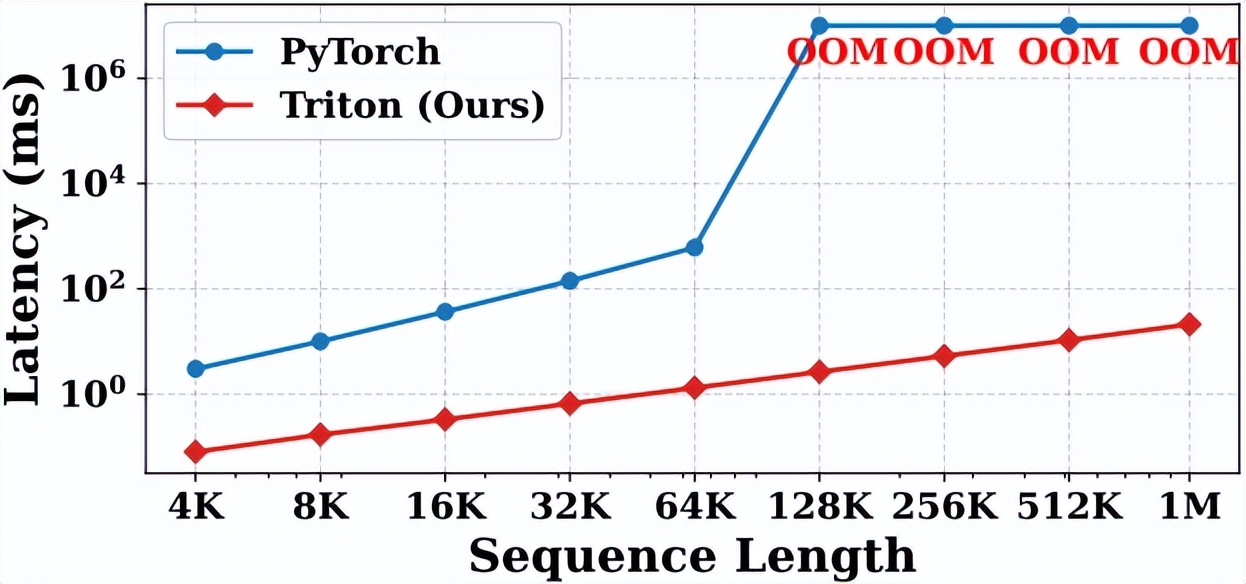
Figure 2. Comparison of Triton Kernel Acceleration Effects
The authors implemented a hardware-friendly efficient solution using Triton, achieving a 24.4 times acceleration at 64K context compared to the PyTorch implementation.
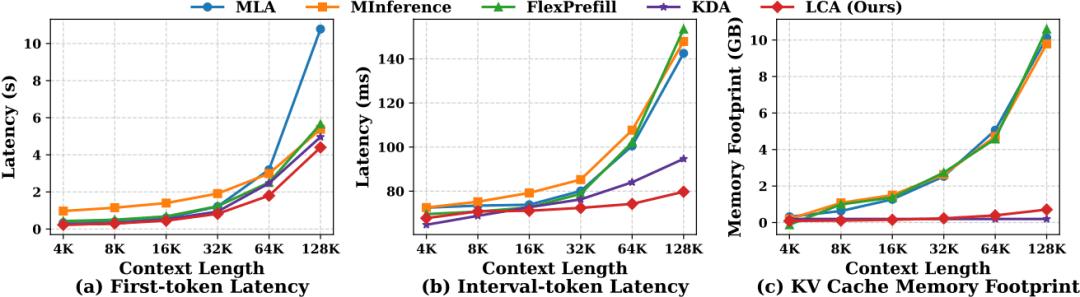
Figure 3. Efficiency Performance at Different Context Lengths
At a context length of 128K, the efficient LCA achieved 2.5 times pre-fill acceleration compared to the original MLA, reducing 90% of the KV cache and lowering decoding latency by 1.8 times.
2. Performance Maintenance for Long Contexts
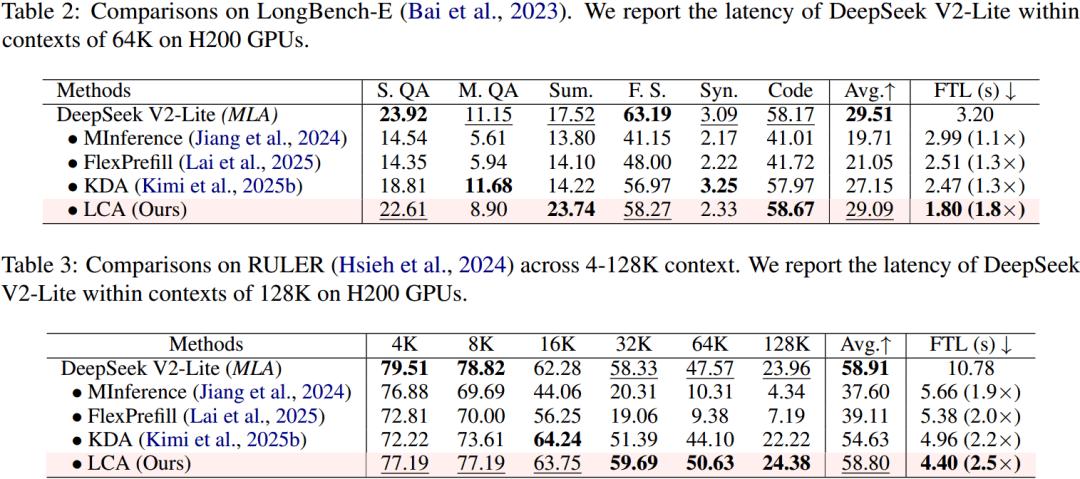
Comparison of Long Context Benchmark Performance
In long context benchmark tests such as LongBench-E and RULER, LCA significantly improved efficiency while maintaining performance comparable to the original MLA. The performance of LongBench-E is nearly on par with standard MLA, and RULER 128K results even show slight improvement.
3. No Loss in Short Context Tasks
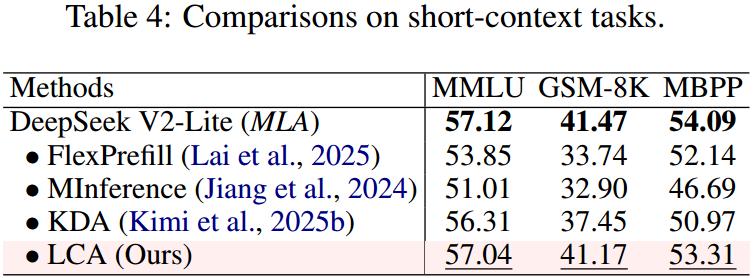
Comparison of Short Context Standard Task Performance
In standard short context tests like MMLU, GSM8K, and MBPP, LCA’s performance is nearly identical to that of the original MLA, indicating that its compression mechanism does not compromise the model’s foundational capabilities.
4. Compatibility with Different Model Scales
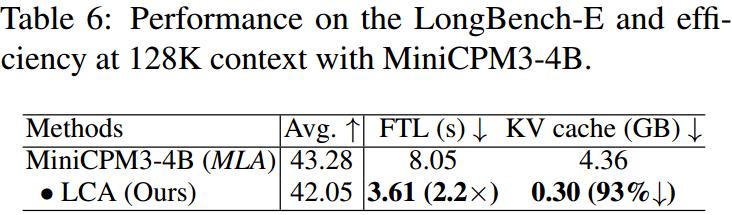
Verification of LCA’s Scalability on MiniCPM3-4B Model
LCA is also effective on the MiniCPM3-4B model, achieving 2.2 times pre-fill acceleration and 93% KV cache reduction, validating its universality across models of different scales.
5. Adaptability to Other Attention Variants
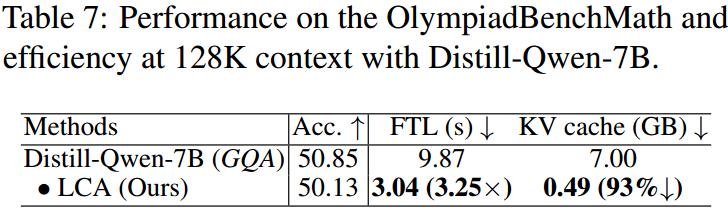
Verification of LCA’s Adaptability to GQA Architecture
LCA’s design does not rely on MLA and can be extended to other attention mechanisms. Experiments show that adapting it to Group Query Attention (GQA) still achieves 3.25 times inference acceleration and 93% cache reduction on the DeepSeek-R1-Distill-Qwen-7B model.
5. Practical Significance
LCA provides important support for the practical deployment of long context LLMs:
- Reduced Deployment Costs: No additional parameters or modules are needed; it can be plug-and-play to replace existing MLA/GQA modules in current models.
- Lower Hardware Threshold: A 90% reduction in KV cache means that much longer contexts can be handled with the same memory.
- Improved Response Speed: The 2.5 times pre-fill acceleration significantly enhances user experience, especially in applications requiring real-time interaction.
- Maintained Model Capability: Efficiency improvements are achieved without sacrificing the model’s performance across various tasks.
6. Conclusion
LCA cleverly unifies KV cache reduction and computational complexity reduction by directly compressing context in the latent space. Its decoupled semantic-position processing strategy, theoretically guaranteed approximation error bounds, and extensive experimental validation make it a powerful solution for efficient long context modeling. This work has been accepted by ACL 2026, and we look forward to more researchers and developers further advancing long context technology based on this foundation.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.